
27/11/2017
Internet
Web
Dernier chapitre dans la présentation du web. Nous allons parler du protocole HTTP (HyperText Transfer Protocol), sur lequel se base le web. Ce protocole permet d’échanger des documents hypermédia entre un client (un navigateur Internet) et un serveur. Le client ouvre une connexion, émet une requête et attend une réponse. Nous parlerons aussi des organismes gérant le web.
Un petit historique
HTTP 1 & 1.1
Le protocole a beaucoup évolué depuis ses débuts. Au départ (en 1991), http ne pouvait transférer que des fichiers. Depuis la version 1.0 (1996) le protocole permet de transférer tout type de fichiers comme des images, vidéos, scripts, feuilles de styles… Le type de la ressource est précisé dans l’entête de la requête ou de la réponse, via le type MIME (Multipurpose Internet Mail Extensions).
En 1997 nous avons une nouvelle version, la version 1.1. Elle permettait entre autre d’améliorer les performances en permettant de réutiliser la même connexion. C’est la version la plus répandue aujourd’hui.
HTTP 2
Le protocole est largement améliorable mais il aura fallu attendre pratiquement 20 ans, avant que les différents acteurs s’entendent sur une nouvelle version du protocole. La version 2 a été finalisée en 2015 et est en cours de déploiement.
Cette nouvelle mouture se veut tout d’abord à 100% rétrocompatible, afin de ne pas à avoir à changer le code des différentes applications utilisant les versions anciennes du protocole. En gros les méthodes, statuts, codes erreur sont conservés.
Le but principal de HTTP2 est de rendre les requêtes moins coûteuses en ressources, afin d’améliorer les performance sur des devices où la qualité du réseau varie beaucoup. HTTP2 permet le multiplexage pour échanger différents messages en même temps et utilise la compression des entêtes.
HTTP décrit comment les messages sont échangés avec un serveur mais au niveau plus bas HTTP se base sur les protocoles TCP et IP. Actuellement HTTP peut ouvrir plusieurs connexions TCP en parallèles ce qui peut congestionné le réseau. Avec HTTP 2 le but est de regrouper ces échanges sur la même connexion TCP. HTTP 2 n’impose pas de sécuriser les échanges en cryptant les informations via un chiffrement TLS (SSL). HTTP limite le surcoût dans le chiffrement car en 2017 tous les échnges réseaux devraiênt être cryptés.
Aujourd’hui quand vous ouvrez une page web, le code HTML arrive, il est parsé, on charge ensuite les styles, les images. Quand on regarde le nombre de requêtes lors de l’ouverture d’une page d’un navigateur, ce dernier peut être très important. Maintenant grace au multipexage, les différents éléments pourront être envoyés en même temps.
En HTTP2 un client peut maintenir une connexion même si l’utilisateur clique sur un bouton ou choisit de fermer une connexion. Ceci permet au serveur de pouvoir faire du push.
Appel HTTP
Comme je l’ai indiqué en entête de ce chapitre, le client est à l’initiative des échanges. Nous avons toujours 3 étapes.
-
Ouverture d’une session le plus souvent HTTP (surcouche de TCP)
-
Envoie d’une requête
-
Le serveur interprète la requête et renvoie un statut (un code) ainsi que les données éventuelles.
Une requête HTTP est assez simple. L’écriture est masqué par les logiciels clients comme votre navigateur web. Mais il est important de comprendre comment marche le protocole. Pour celà nous allons invoquer manuellement un serveur HTTP
Lancez une commande telnet en invoquant un serveur web. Je prends dans mon exemple le site web dev-mind et je précise le port (80 est le port par défaut d’un serveur web)
telnet www.google.fr 80On écrit ensuite la requête. Vous devez indiquer plusieurs informations
Une première ligne avec * la méthode a appelé (GET, POST, DELETE…), * La ressource à charger (dans mon exemple ci dessous c’est / qui pointe vers défaut vers la page index.html) * Le protocole utilisé * Et d’autres lignes avec les différents paramètres placés dans le header
GET / HTTP/1.1
Host: www.google.fr
Accept-Language: frJe demande ici de charger la ressource accessible à la racine du serveur de google. Le serveur HTTP me renvoie en réponse la page index.html
HTTP/1.1 200 OK
Date: Tue, 12 Jul 2016 07:10:23 GMT
Expires: -1
Cache-Control: private, max-age=0
Content-Type: text/html; charset=ISO-8859-1
P3P: CP="This is not a P3P policy! See https://www.google.com/support/accounts/answer/151657?hl=en for more info."
Server: gws
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
Set-Cookie: NID=81=UHO0sJ4yG6qTdp-5kdQO1YwAJbfrH-YBS0I3XnYdZQXuwXd1kK_Eo7PWlD6y33DVZG-MvuJfsqH7lmj7EOgcdaYXCRWCk-7fmD0bymGa-4qf3ILt8pBJdwNHWADYyn6R; expires=Wed, 11-Jan-2017 07:10:23 GMT; path=/; domain=.google.fr; HttpOnly
Accept-Ranges: none
Vary: Accept-Encoding
Transfer-Encoding: chunked
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="fr"><head><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image">
//………..
</html>La première ligne contient le statut de la requête : un code et un libellé. Quand tout se passe bien vous obtenez un code 200 et le libellé OK.
Vous avez ensuite plusieurs informations dans le header de cette réponse comme le content type, des données d’identification, les informations pour savoir si la ressource peut être mise en cache ou non….
Les méthodes HTTP utilisables dans les requêtes
Le protocole HTTP permet d’exécuter différents types d’action sur le serveur. Voici les principales méthodes disponibles.
-
GET: permet de récupérer une ressource sur le serveur. Suivant l’implémentation, le serveur HTTP peut prendre en compte les paramètres placés dans l’entête de la requête (par exempleIf-Modified-Since:,If-Unmodified-Since:, …) -
HEAD: identique àGETmais ne contient aucun message -
PUT: permet de mettre à jour une ressource sur le serveur -
POST: effectue une action comme une création ou un envoi de données d’un formulaire HTML -
DELETE: suprime une ressource -
OPTIONS: permet de vérifier si le serveur implémente ou accepte différentes actions. Cette méthode est par exemple utilisée pour régler les problèmesCORS (requêtes multi origines)et faire une preflighted cross-origin request
Code HTTP retournés dans les réponses
Pour chacun des appels une réponse est retournée au client pour lui dire si ça requête a pu êre réalisée ou non. Cette réponse contient un code constitué de 3 digits. Il existe de nombreux codes répartis en 5 catégories (le premier permet de définir cette catégorie)
1xx Information
Par exemple un code 100 (Continue) est renvoyé pour indiquer que le client peut continuer à envoyer sa requête
2xx Succès
Le code le plus courant est 200 (OK). Il est envoyé lorsqu’une requête est exécutée avec succès. Vous pouvez parfois avoir un code retour 206 (Partial Content) pour vous indiquer que d’autres paquets seront envoyés plus tard mais que linformation peut commencer à être affichée (code utilisé lors du chargement des images et des vidéos par exemple).
3xx Redirection
Les codes >= 300 permettent d’indiquer que la requête était valide mais qu’aucune ressource ne sera renvoyé. Un code 301 (Moved Permanently) indique que la ressource a été déplacée. Un code 304 (Not Modified) est renvoyé quand le client posède déjà la dernière version de la ressource.
4xx Erreur côté client
Ce code est renvoyé quand la requête envoyée est invalide 400 (Bad Request), incomplète, ou que la ressource demandée n’a pas été trouvée : 404 (Not Found). Les code 4xx sont aussi utilisés pour les problèmes de sécurité : 401 (Unauthorized), 403 (Forbidden)
5xx Erreur côté serveur
Les erreurs côté serveurs renvoient un code en 5xx. Par exemple l’erreur 500 (Internal Server Error) est la plus générique.
Voici un bon moyen mnémotechnique (tiré d’une conférence de Guillaume Laforge) pour vous souvenir des catégories
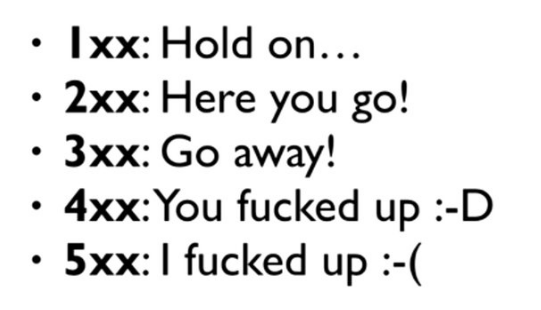
Les headers HTTP
Afin d’affiner les requêtes et les réponses, des paramètres peuvent être ajouté dans l’entête des message. Vous pouvez ajouter vos propres données dans ces headers. Le principe est de pouvoir transférer des informations entre le client et le serveur.
Je pourrai lister tous les entêtes standards interprétés par les navigateurs mais l’intérêt est limité. Vous pouvez trouver la liste sur le site de Iana (Internet Assigned Numbers Authority) antenne de l’ICANN.
Ce qu’il est intéressant de savoir c’est qu’il en existe différents pour traiter automatiquement certaines problématiques. Le site développeur web (MDN) de Mozilla propose une classification intéressante : authentification, cache, CORS…
Organismes de régulation
Des initiatives locales
Je parle de régulation car ce terme est dans la bouche de toutes les autorités dans le monde. Le web a été créé pour être un espace libre mais l’argent et les données personnelles sont de tel enjeux que privés et gouvernants font tout pour prendre le contrôle.
Heureusement ce n’est pas simple. Mais Internet devient de moins en moins un espace de liberté. Chaque pays mais en place des autorités de régulation quand il n’y a pas de la censure ou autre mécanisme pour contrôler les internautes.
Le W3C
Après ce petit apparté je vais parler de l’organisme qui devrait être le seul maître à bord. Il s’agit du W3C acronyme de World Wide Web Consortium. Cette association fondée en 1994 par Tim Berners-Lee a pour leitmotiv : “un seul web partout et pour tous”.

Le W3C est l’organisme qui s’occupe de la standardisation des technologies utilisées dans le web : HTML, CSS mais aussi XML, XSL, SVG, PNG…. Le consortium regroupe un peu moins de 400 entreprises et a plusieurs antennes aux Etats Unis en Europe, en Asie…
Le W3C planche sur des recommandations. Voici par exemple la recommandation définissant HTML5 https://www.w3.org/TR/html5/. Les fabricants peuvent suivre ou non les recommandations et par conséquent nous pouvons avoir parfois de grosses différences d’implémentations.
Une recommandation peut passer par les états suivants * Working Draft (WD) (brouillon de travail), * Last Call Working Draft (dernier appel), * Candidate Recommendation (CR) (candidat à la recommandation), * Proposed Recommendation (PR) (recommandation proposée), * W3C Recommendation (REC) (recommandation du W3C)
Le WHATWG
WHATWG (Web Hypertext Application Technology Working Group) est une communauté de personnes dont le but est de faire évoluer le web. Cette fondation a été créée par des mécontents du W3C en 2004. On retrouve la fondation Mozilla, Opéra, des personnes de chez Apple.
Le but est de répondre à la lenteur du W3C sur certains sujets comme HTML, les web workers,… Au final les 2 organisations travaillent ensemble pour faire avancer le web.